
XDAG技术详解7-挖矿POW
XDAG技术详解7-挖矿POW
作者:社区成员Larry
难度与算力
-
难度
根据block hash计算所得:
(power(2, 128)-1)/(little-endian-int(hash) / power(2, 160))。 -
算力
单节点的算力是直接统计出来的hash次数。
全网算力是根据难度值转换出来的,难度取的是4个小时的平均值。
挖矿流程
下面是pool和miner之间的挖矿交互流程。
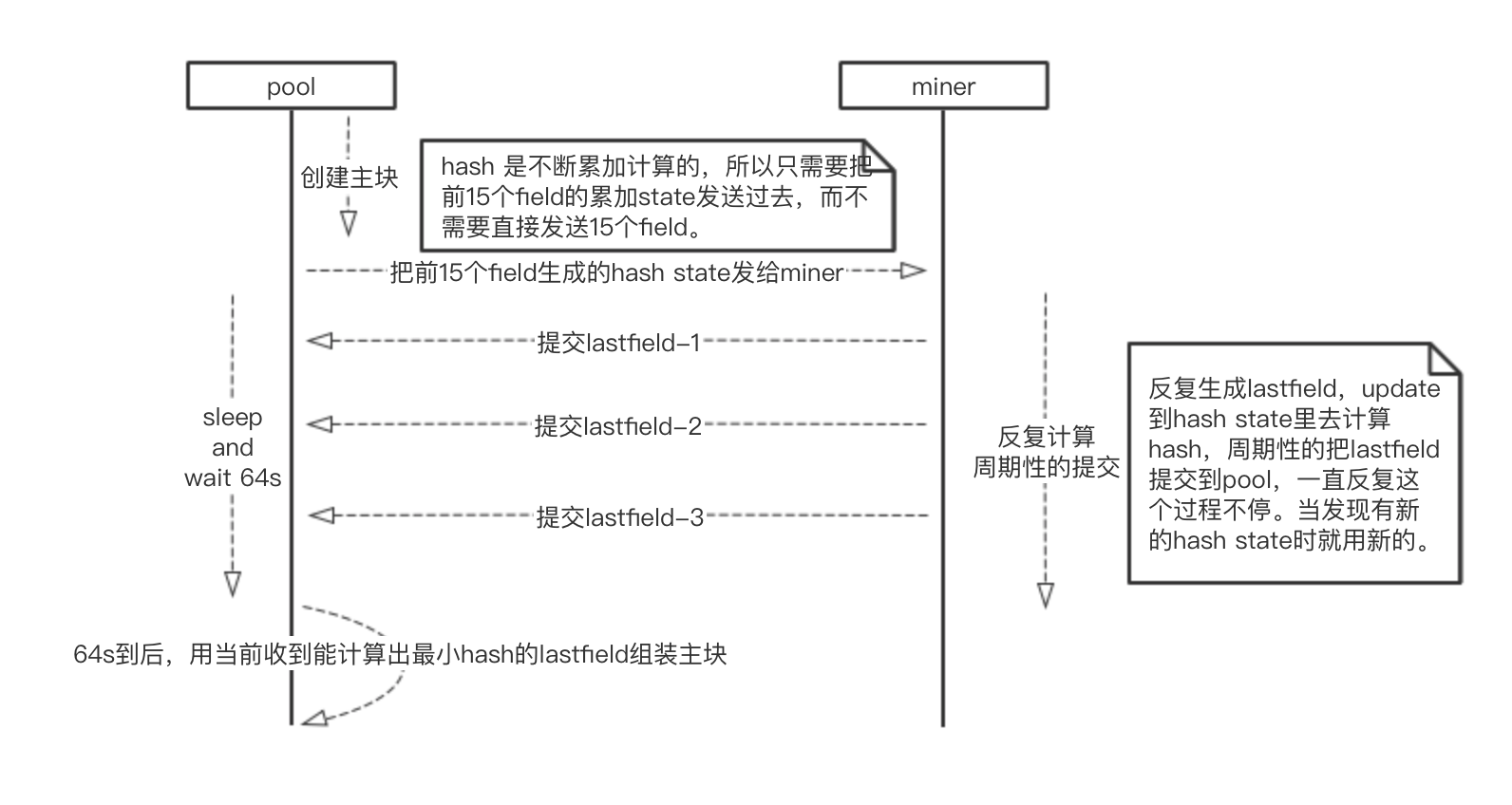
image-20191201134454086.png
pool端:
-
每个周期(64s)开始时,pool创建一个主块。
这个主块会尽可能更多的链接截至当时已知的孤块(个数不超过可用的field),有可能无法链接完所有当前的孤块,则多出来的孤块只能等待下个周期的主块继续链接,也就是有部分交易的确认时间会延长。
为了使得每个周期的孤块尽可能的被尽早链接(确认交易),链接块起到了关键作用,如果链接块生成的足够快且足够多,使得整个图收敛到足够小的宽度上,比如孤块顶点小于12,则原则上可以一次都被主块链接。
-
计算前15个field的hash累加中间值(hash state),并发送给各个矿机。
pool发送任务给各个矿机时,并不是直接把整个block内容发送出去,而是只发送了前15个field计算的hash中间变量,这里叫hash-state。
这个hash-state,加上一个lastfield再计算一次hash,效果等同于一次计算16个field的hash结果,不会因为没有原始的前15个field而不同。这样pool就只需要发送一个中间变量给矿机,发送的字节数会大大减少,同时又不影响计算结果。之所以可以这样发送,是由hash算法的特性决定的,后面单独说明。
-
发送完成后,pool进入等待提交状态。
pool进入等待期后,各个矿机会不断周期性的提交自己探索出的lastfield。
pool每次收到新的lastfield,都跟当前miner已知的最小进行比较,如果更小则保存在miner状态中。
-
周期结束,pool打包生成主块。
在周期结束时刻,pool把各个矿机提交的lastfield拿出来,一个个跟hash-state做一次合并计算,看谁提交的lastfield能得到最小的hash,也就是最大的难度,谁的提交就胜出。pool就用这个lastfield完成主块的组装,然后加上自己的签名,提交到网络上去。
至此,一个新的主块就产生了,但是每个pool都会用同样的方法产生一个自己的主块,所以最终只能有一个主块竞争胜出,成为真正的链上主块。
-
主块与周期的关系
通过前面的分析可以看出,主块时间戳与自身链接的交易周期实际上差了一个周期。
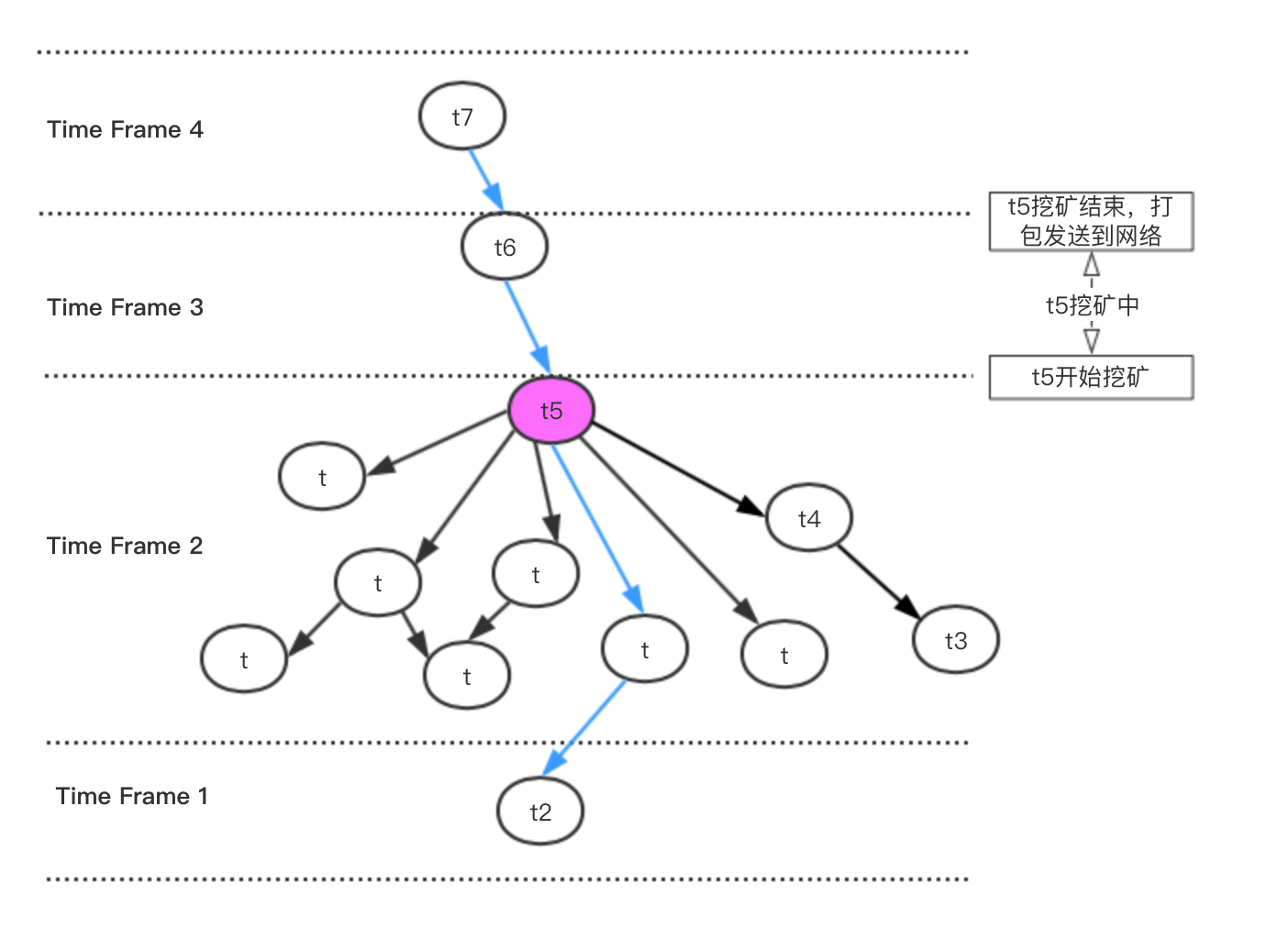
image-20191204130023570.png
如上图所示,t5作为Time Frame2周期的主块,链接的是Time Frame2周期的交易,但是t5真正打包成功生成主块的时间戳是Time Frame4周期的起点,或者说Time Frame3周期的终点。
也就是说,主块时间戳所在的周期,是主块中交易所在周期的下一个周期。
miner端:
-
miner接收到一个新的task
task包含一个hash-state。
-
miner不断探索最小hash
不断生成随机数,填充组成一个新的lastfield,尝试跟hash-state组合后计算hash。
在一个固定周期中,选择上面多次计算中结果中最小的一个,提交给pool。这个固定周期通常至少要小于32s,以此保证一个64s中至少提交过一次。通常会尽可能短,这样能把因跨周期计算的算力浪费最小化。但不能过于频繁的提交,浪费资源。
Hash算法
前面提到,挖矿中pool并不需要把block的全部数据发给miner,只需要发送前15个field累加出的hash-state,miner找到lastfield后直接与hash-state组合就可以得到真正的block hash。之所以可以这么做,与hash算法特点有关。
假设总block是512字节,hash结果是32字节,我们定义一种叫Stupid-Hash的算法,算法过程如下:
- 先设置一个32字节的最终数组,result-array。
- 把block的第一个32字节先复制到result-array。
- 接着把第二个32字节按照某种累加运算法则,与当前的result-array运算一次,结果放回result-array。
- 后面每一个32字节都按照相同的思路与result-array运算并把结果放回result-array。
- 直到最后一个32字节迭代计算完成,最后一次得到的result-array就是最后的hash结果。
在Stupid-Hash算法下,对一个很长的二进制数据做hash,可以把累加到中间任意步骤的result-array保存起来,发送给另一个机器,另一个机器用result-array加上剩下的数据继续这个hash算法,得到的结果与第一个机器把这个计算一直进行到底得到的结果是一致的。
xdag中hash算法的思路与这个Stupid-Hash的思路是一致的,只不过真实hash算法(sha256)中间的运算过程更复杂一些,但是整体计算思路没有不同。
mining收益分配
单个pool链接了众多miner,当挖矿成功后,需要在各个miner间分配收益。
分配基本策略主要是依据各个miner在当前周期中探索到的最大难度,比如有三个 miner,各自在当前task周期的最大难度是1、2、3,最终给第一个miner的比例就是1/(1+2+3)。
在这个基本分配策略之外,增加了一些特殊分配。
- 给基金会账户一个固定比例的分成。
- 给pool账户一个固定比例的分成。
- 给找到最小hash的miner一个其难度比例之外的特殊分成。
上面这些分配比例可以在pool启动的时候自由配置。
T周期对T-15周期的挖矿进行分配。
钱包与pool的交互
在当前的实现中,对pool来说,钱包实际上与miner角色一样,pool对两者的处理策略一致。差别在于钱包不做挖矿,也不提交计算。
pool会周期性的向钱包推送钱包账户的余额下去,钱包并不向pool去查询余额,只查看本地存储已知的账本。


